단순하게 처음부터 끝까지 일일히 검사하는 브루트 포스법은 간단하지만 비효율적이라는 단점을 가지고있습니다. 이런 단점을 보완하고자 고안된 방식이 Boyer Moore법이며, 이 방식이 많이 사용되고 있습니다.
1. Boyer Moore 법
Boyer Moore 법은 브루트 포스와는 다르게 키의 마지막 글자부터 처음 글자 순서로 검사를 진행합니다. 검사를 진행하다가 불일치하는 부분이있으면 그 부분만을 집중적으로 검사하고 그 칸수만큼 훌쩍 뛰어넘어 검사를 진행해서 검색 속도를 향상시키는 방법입니다.
다음 배열에서 'ABC'를 검색하려고 합니다. 우선 문자열에 키를 맞춘후 제일 마지막 요소 부터 검사를 시작합니다. 검사를 시작하는데 불일치하는 지점이 발견되었습니다. 그러면 불일치 지점에 대해 키를 이동시켜 비교를 합니다.



키를 대조한 결과 해당 불일치 지점에 키에 존재하지 않는 요소입니다. 그래서 1번째, 2번째를 검색할 필요가 없이 검색 인덱스를 4번째 요소로 건너뛰어서 검사를 진행하게 됩니다. 그리고 건너뛴 상태에서 다시 한 번 마지막 요소부터 비교하며 같은 과정을 반복하게 됩니다.
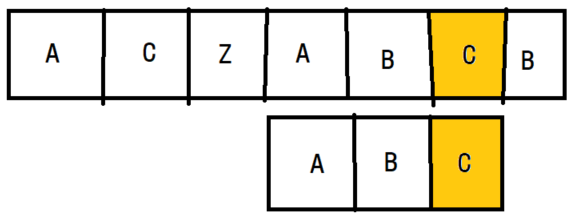


이런 과정의 진행 덕분에 불필요한 요소를 검사하지 않고 훌쩍 뛰어넘을 수 있어서 굉장히 편리한 알고리즘입니다.
2. Boyer Moore 구현
export const boyerMoore = (str, key) => {
let strPointer; //문자열에서 현재 위치 포인터
let keyPointer; //키 문자열에서 현재 위치 포인터
let strLength = str.length;
let keyLength = key.length;
let skipTable = new Map(); //스킾 테이블
//스킾 테이블을 모두 키의 길이만큼 설정
for (let i of str) {
skipTable.set(i, keyLength);
}
//스킾 테이블의 요소 중 키의 요소들을 수정
for (strPointer = 0; strPointer < keyLength; strPointer++) {
if (skipTable.has(key[strPointer])) {
skipTable.set(key[strPointer], keyLength - strPointer - 1);
}
}
//본격적인 검사 부분
while (strPointer < strLength) {
//키 포인터의 검사 시작부분은 키의 마지막 부터
keyPointer = keyLength - 1;
while (str[strPointer] === key[keyPointer]) {
//키 포인터가 시작(0)까지 오면 검색 성공
if (keyPointer === 0) {
return console.log("검색 성공, 인덱스: " + strPointer);
}
strPointer--;
keyPointer--;
}
//불일치하면, 스킾 테이블에 저장된 길이 혹은
//키의 길이-현재 키 포인터 중 큰 것만큼 건너뛰기
strPointer += Math.max(skipTable.get(str[strPointer]), keyLength - keyPointer);
}
return console.log("검색 실패");
};
브루트 포스에 비하면 확실히 구조가 복잡해졌습니다. 그런데 중간에 스킾 테이블이란 뭘까요?
스킾 테이블은 키 문자열의 길이 n에 따라서 불일치하는 경우 어떤 문자를 만나면 얼마만큼 건너뛸지를 저장한 표입니다. 여기서는 A~Z까지 영어 대문자만을 이용한 문자열이므로, A~Z까지 모든 문자에 대해 몇 칸을 뛰어넘을지 저장된 표입니다.
위의 예시에서 ABAC이 키라면 C~Z까지는 모두 키 문자열의 길이인 4를 스킾 테이블에 저장하고 A는 1, B는 2만큼 저장하게 됩니다. 그래서 검색 실행시 불일치 부분을 찾았을때 불일치한 키 문자에 저장된 스킾 테이블을 보고 몇 칸을 스킾해야 겠구나 하고 프로그램이 알 수 있게 됩니다.
import {boyerMoore} from './study-code/search/boyer-moore.js';
const str = 'ABCXDEZCABACABAC';
boyerMoore(str, 'ABAC');
boyerMoore(str, 'CCC');
https://github.com/Bam-j/algorithm-study/tree/main/study-code/search
GitHub - Bam-j/algorithm-study: 블로그 알고리즘 정리 포스트 코드 수록 + 코딩 테스트 코드 수록
블로그 알고리즘 정리 포스트 코드 수록 + 코딩 테스트 코드 수록. Contribute to Bam-j/algorithm-study development by creating an account on GitHub.
github.com
'Programming > 알고리즘' 카테고리의 다른 글
| 브루트-포스 법 (0) | 2021.11.10 |
|---|---|
| 이진 검색 (0) | 2021.11.10 |
| 선형 검색 (0) | 2021.11.09 |
| 하노이 탑 (0) | 2021.11.08 |
| 재귀 알고리즘 - 유클리드 호제법 (0) | 2021.11.08 |




댓글